Multi-Layer Perceptron (MLP)
MLP in Python 3
Scikit-Learn
The above code is an implementation of a multi-layer perceptron using SciKitLearn. This is a great way to implement it as it is a quick and elegant. The code that defines the architecture of the MLP is the following line:
The key thing to understand in the above code is that the hidden_layer_sizes parameter controls the number of layers and their depth. So in the above code “hidden_layer_sizes = (450,200)” means there are two layers, one with depth of 450 nodes and the second with depth of 200 nodes. If you wanted a third layer “hidden_layer_sizes = (450,200,50)” would create three layers with 450, 200 and 50 nodes respectively.
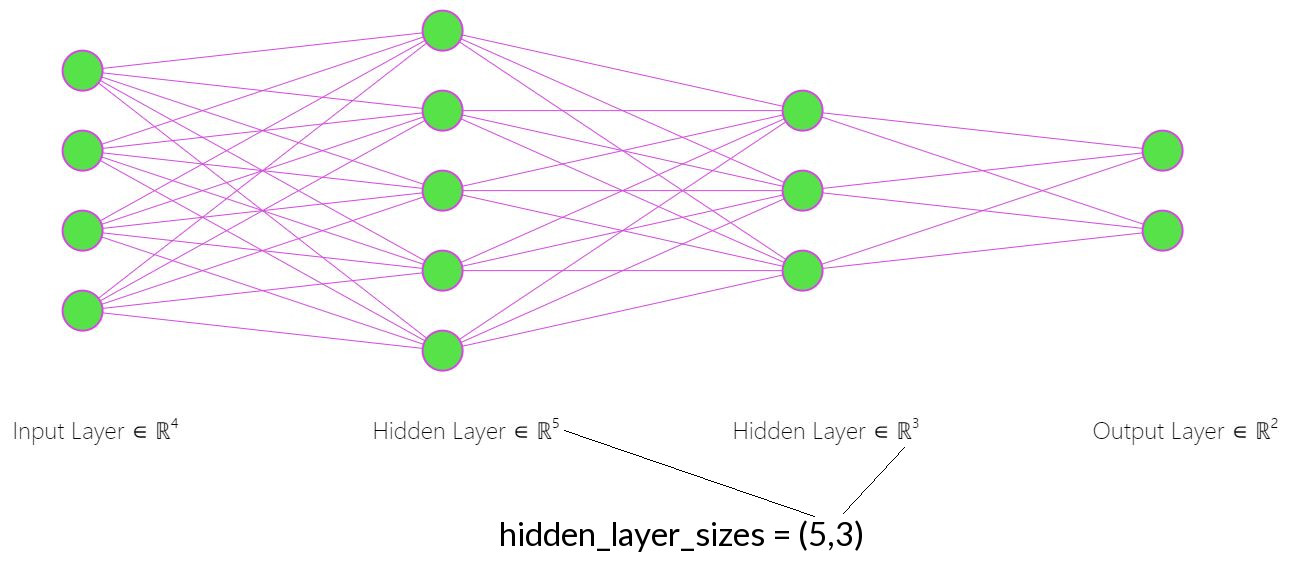
max_iter is the number of epochs.
The parameter ‘batch_size’ controls how many variables we use in training the network in a single pass. The main reason we use batches is that it is often not possible to load all the data in memory. However, it can be better to use batches as it may result in more generalized results as well preventing overfitting to the training data.